
我們再來回顧一次我們的需求:
那我們Django部分的主角Celery需要做什麼?
首先,如果儲存與更新文章一定需要時間去解析,並且在知識庫拿到用戶問題,最終返回答案的過程也是需要時間去運行相關排程。因此為了不阻塞主進程,需要有額外的進程來處理這些子任務,而這也就是Celery的功能
今日重點:
為什麼這個專案需要處理向量資料,而向量資料庫又能做到什麼?
如果根據我們之前建立的資料來進行查詢,我們如果輸入LLM就只能查到包含LLM這個字符串的結果,但是我們的目標可能是ChatGPT、Claude…等等。
而向量資料中每一個向量對應一個物件或是項目,如果能夠準確的建立這些向量,那麼我們就能夠過語意來找尋相似的單字而不是根據單字的名稱來尋找
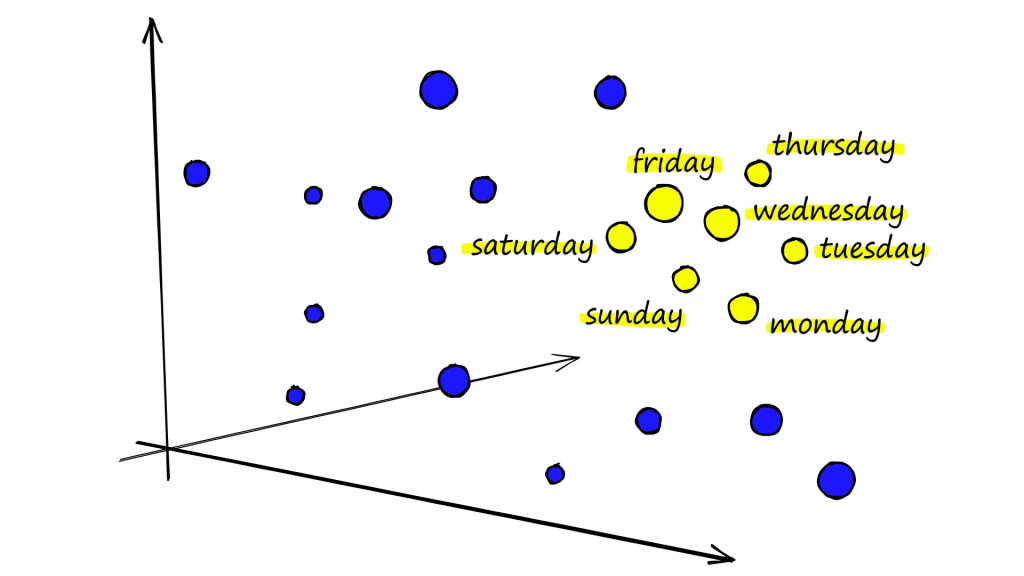
圖源:https://www.pinecone.io/learn/series/nlp/dense-vector-embeddings-nlp/
當我們要儲存資料到向量資料庫時,可以設定不同的算法,來決定資料的維度:最後儲存的向量資料
如果是使用Python或是javaScript開發,並且追求開源且快速開發的話,使用Chroma是很好的選擇
https://github.com/chroma-core/chroma
具備以特點:
因為在這個專案中,我們想要快速建立相關的應用且考慮到與Python的高度適配性,因此選擇Chroma
現在大型語言模型如雨後春筍的出現,而各家模型又有各自的API,並且剛剛提到過的向量資料庫也是百百種。如果有一個框架,能夠統整出相關的API,讓我們能夠隨時替換掉LLM或是向量資料庫而不需要重新開發,在開發上我們就只需要專注在邏輯實現,以及了解不同LLM的特色就好。
LangChain 的核心理念正是為了解決該問題而設計的。它提供了一個抽象層,使得開發者可以輕鬆切換不同的 LLM 和向量數據庫,而無需大幅度修改程式碼
LangChain具備以下特點:
LangChain 提供了統一的接口來與不同的 LLM 交互。無論是 OpenAI 的 GPT還是開源的 LLaMA,都可以通過相同的 API 調用
LangChain 為各種向量資料庫(如 Chroma、Pinecone等)提供了統一的接口
LangChain 引入了鏈(chain)的概念,允許將多個操作組合成一個流程
LangChain 提供了強大的提示(prompt)管理功能
LangChain 提供了多種記憶(memory)組件
通過提供這些抽象和工具,LangChain 讓開發者能夠:
這種方法大大降低了 AI 應用開發的門檻,同時提高了開發效率和應用的可維護性
但是因為LLM應用的開發迭代速度很快,也因此LangChain的相關套件也是很常浮動
雖然會說LangChain本身像是瑞士刀一樣的方便,但是現實是這個工具隨時都在改變
雖然核心概念沒變,但是方法的名稱、參數調用的名稱等等都有很多變化
加上許多方式沒有一個非常固定統一的邏輯,很容易在學習沒多久後之前用的方法都被棄用了,套件的迭代速度也很快。因此也有人比較著重在如何使用prompt來達成目的,API還是自己架設
在這個專案中不會著重在LangChain非常強大的Chain與prompt template上,只會做非常基本的操作
許多專案中使用的方法,即使是第一次看到也能
在進到開發功能之前,說明一下資料處理的流程:
文章儲存或是更新時:
用戶輸入資料時:
Celery是一個分散式任務隊列系統,用於處理異步任務和定時任務
整個系統的組成部件如下:
運作流程如下:
[Client] --發送任務--> [Broker/Queue] --分發任務--> [Worker]
[Worker] --執行任務並存儲結果--> [Backend] --獲取結果-->[Client]
那為什麼一開始會說Celery是一個分散式任務系統,因為我們可以藉由建立多個Worker來達到多進程的架構,當發布任務時,主進程(Django繼續做他的事情)而任務則是交給Celery來處理
同時也能給Celery配置的多線程的設計,來讓Celery能夠負擔繁重的任務
poetry add celery
poetry add django-celery-beat # 在這次專案用不到,是處理定期任務時才需要
poetry add django-celery-results # 需要儲存任物結果時安裝
poetry add flower # 需要監控celery任務的狀態時安裝,本次專案不會著墨
# settings.py
INSTALLED_APPS = [
...
"django_celery_results",
...
]
# celery配置
CELERY_BROKER_URL = f"redis://:{REDIS_PASSWORD}@{REDIS_HOST}:{REDIS_PORT}/0"
CELERY_TIMEZONE = "Asia/Taipei"
# celery結果存儲
CELERY_RESULT_BACKEND = "django-db"
# celery消息格式配置
CELERY_ACCEPT_CONTENT = ["json"]
CELERY_TASK_SERIALIZER = "json"
CELERY_RESULT_SERIALIZER = "json"
# celery 超時時間
CELERYD_TASK_TIME_LIMIT = 60 * 10
# celery 儲存結果的過期時間 默認1天過期 如設為0則永不過期
CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24
# celery 任務限流
CELERY_TASK_ANNOTATIONS = {"tasks.add": {"rate_limit": "10/s"}}
# 每個worker執行多少任務後會被殺死,預防記憶體泄漏
CELERYD_MAX_TASKS_PER_CHILD = 100
# 消除警告
CELERY_BROKER_CONNECTION_RETRY_ON_STARTUP = True
# celery.py
from celery import Celery
from django.conf import settings
import os
# set the default Django settings module for the 'celery' program.
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "documind.settings")
# create a new Celery instance
app = Celery("documind", broker=settings.CELERY_BROKER_URL)
# Using a string here means the worker doesn't have to serialize
app.config_from_object("django.conf:settings", namespace="CELERY")
# Load task modules from all registered Django app configs.
app.autodiscover_tasks()
# __init__.py
from .celery import app as celery_app
__all__ = ("celery_app",)
在celery.py中,設置一個新的celery實例對象,並且將settings.py中的配置配置在該實例上,此外使用autodiscover_tasks方法,可以自動偵測所有app下有配置@shared_task裝飾器的任務
在__init__中,確認專案啟動時能夠正確配置到該celery實例
遷移celery_result相關的表格到資料庫
python3 manage.py makemigrations
python3 manage.py migrate
Celery -A documind worker -l info
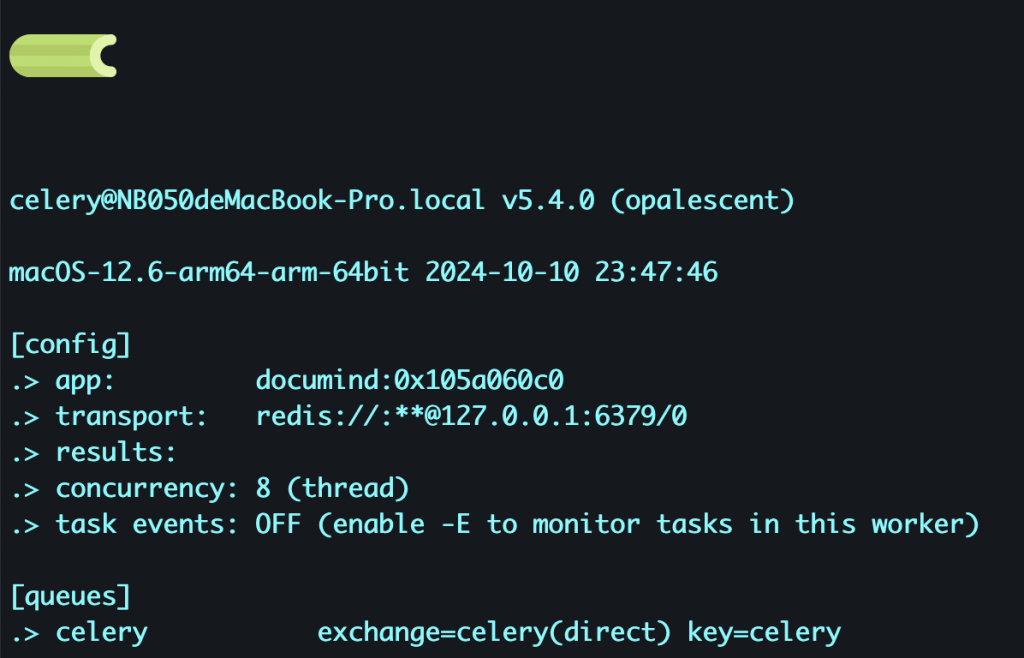
那我們這邊先確認配置的celery是否能夠成功運作
from celery import shared_task
import time
@shared_task(max_retries=3)
def add_number(x, y):
time.sleep(10)
return x + y
from django.http import HttpResponse
from .tasks import add_number
def task_view(request):
task_result = add_number.apply_async((1, 2))
return HttpResponse(
f"{task_result.id} is the task id<br />result status: {task_result.status}"
)
這邊用了apply_async方法來啟動任務,在Celery中有幾中方式來讓worker執行任務:
delay與apply_async,兩種方式的區別在於後者可以更多的設置執行任務的細節
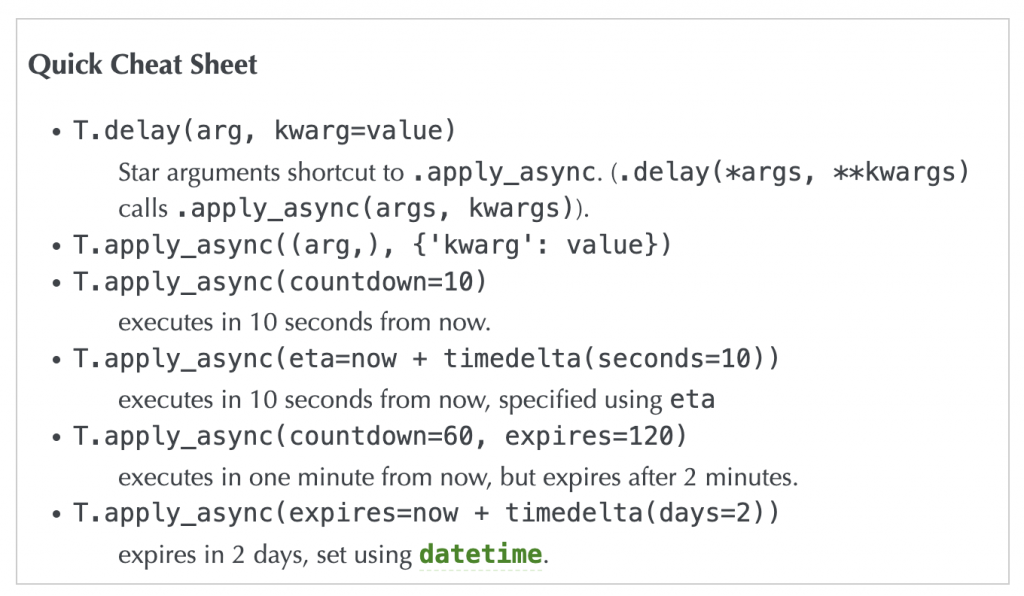
圖源:https://docs.celeryq.dev/en/latest/userguide/calling.html#basics
# documind.urls.py
urlpatterns = [
path("task/", views.task_view, name="task"),
...
]
確認有真的接收到該任務
[tasks]
. documind.tasks.add_number
當我們嘗試調用該路由時,可以在畫面看到
21004792-9d03-4505-a4c9-4d1fe22a78fe is the task id
result status: PENDING
而啟動Celery的終端機
[2024-10-11 19:48:38,082: INFO/MainProcess] Task documind.tasks.add_number[21004792-9d03-4505-a4c9-4d1fe22a78fe] received
[2024-10-11 19:48:48,137: INFO/MainProcess] Task documind.tasks.add_number[21004792-9d03-4505-a4c9-4d1fe22a78fe] succeeded in 10.055313165998086s: 3
我們可以知道幾件事情:
確認我們的Celery本身配置沒問題後,就進到專案開發吧
下一篇就把以下功能一一完成:

 iThome鐵人賽
iThome鐵人賽